
Twitter/X, Mastodon or LinkedIn, what works best for communicating scientific findings? I got the numbers for you!
This website is almost ten years old, and still going strong. I am far from done with its main goal, which is the communication of our – I dare say important – scientific findings to a broad audience.
Now, however, for a long time, I have been relying for a significant part on Twitter to get the word out about new stories on this website. Twitter was, at least for scientific collaborators in the broad sense of the term, the best way to reach them.
For a while now, Twitter has gotten into some unwanted turmoil, and many colleagues have jumped the sinking ship. I haven’t jumped yet – not even after its renaming to the ominous ‘X’. Perhaps selfish of me, but I did not want to get off before I found an alternative way of getting the word out. A scientific publication that nobody knows about could better not have been written.
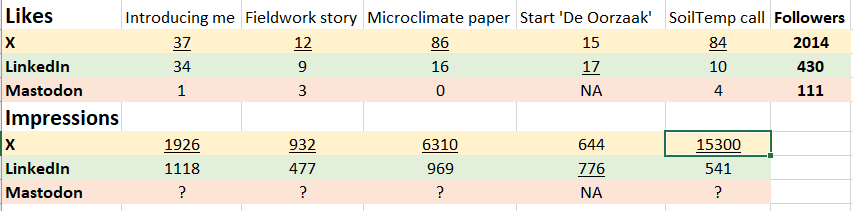
I have kept an eye out for alternatives, and tried a few, just to see what could work. Most promising, initially, was Mastodon, a network that in the days of the ‘free fall’ of Twitter was louded as its best alternative. Unfortunately, although there was a lot of buzz around it, I didn’t really find ‘my people’ there, as reflected in my poor following (see Table below): on Twitter I reach over 2000 people, on Mastodon I have only 111.
Much later, I realized that the best alternative might actually already exist, as many of these new ‘start-up’ social media platforms just don’t find the momentum they need. An existing platform that I had long been overlooking was LinkedIn. While it is mostly seen as an online CV, it also has a community, and a good space for posting updates like this one.
I had been using LinkedIn passively for years, but decided to ramp up my activity on there. Not that much later, I already had my following to 430. Interestingly, while on Twitter/X most of that following consisted of ecologists, on LinkedIn I was connected to the whole spectrum of professional society, largely thanks to the many people I met along the way all the way back from primary school, and through our citizen science projects.
So, it is time for numbers now! For a few months, I decided to promote each and every story on http://www.the3dlab.org on all three of these websites in the same way, and collect the numbers. The output is in that table above, for a various set of posts, ranging from an introduction of myself, a story with pictures from the field, a fascinating microclimate paper, the start of our citizen science project on sound, and the call for data to our growing SoilTemp database.
The conclusion is clear: both for interactions (here I looked at Likes) and impressions, X is still overpowering the others, for almost any kind of content that I want to bring. Despite my efforts, Mastodon has remained a social desert: my posts simply don’t reach anyone who cares (note that Mastodon isn’t showing me the impressions, but even if lots of people would have seen the posts, they did not interact with them).
LinkedIn is a decent second, however. What’s interesting: for the launch of that new project, which is largely in a new scientific field for me and thus less interesting to the ‘crowd’ I have build up on Twitter, LinkedIn even worked better! In general, LinkedIn is at least not that much of a wasteland as Mastodon is.
So, what to conclude:
- Although everyone has been saying Twitter is dead and buried, it’s still the best place to reach a wide audience for me. Some of my most viral tweets even happened after Twitter’s informal burier (not in the table above).
- LinkedIn is the only option of many that actually has given me the idea that my story gets heard, and picked up by relevant people, even outside of academia. That makes it to me a more exciting platform now than Twitter/X.
- Getting a new social media platform off the ground is super hard, even when everyone agrees that they want to get rid of the old establishment. Mastodon is simply not worth the effort for me, and I will abandon it again.
- What about Facebook/Instagram/Tiktok? Facebook is too much focused on personal news for me to regularly post on my scientific findings – it bores the audience there too quickly. Instagram and Tiktok are no platforms for sharing links to this blog, they would require me to rework my communication strategy too drastically.
- So please, everyone, join me on LinkedIn! I think we could make it into one of the most interesting platforms for science communication, if you all join in!













































































































































































































































































































































































































































































































































































































































































































































































































































































")
















")
")





")

































































































")










")









")















































































")





































































































